Subgraphing without subgraph()

{kind=link}
The Challenge of Subgraphing in Gremlin
Subgraphing is a common use case when working with graphs. We often find ourselves wanting to take some small portion of a graph and then operate only upon it. Gremlin provides subgraph() step, which helps to make this operation relatively easy by exposing a way to produce an edge-induced subgraph that is detached from the parent graph.
Limitations and Workarounds
Unfortunately, subgraph() can come with some limitations. One of the limitations that non-JVM based Gremlin Language Variants have, is the lack of support for subgraph() step which is discussed on TINKERPOP-2063. The reason why subgraph() step isn’t supported is because, unlike the JVM which of course has TinkerGraph, there is no Graph object to deserialize the resulting subgraph back into for languages like Python, Javascript and .NET. There are also some graph systems that simply do not support the subgraph() step and therefore fail to produce subgaphs even when using JVM-based langauges.
Depending upon the use case and environment, there are a number of workarounds that a GLV user could consider to deal with this issue. One approach, assuming your graph supports the step, would be to use a Gremlin script to perform the subgraph(). Then, in the same script, some options potentially open up in using that resulting TinkerGraph instance (assuming the server you’re communicating with allows it):
- Write out its data to a
Stringof GraphSON, GraphML, or some other format which you could potentially then process locally in some fashion on the client. - Execute multiple Gremlin traversals on that subgraph (even mutations) and return the results as though you had queried the main graph.
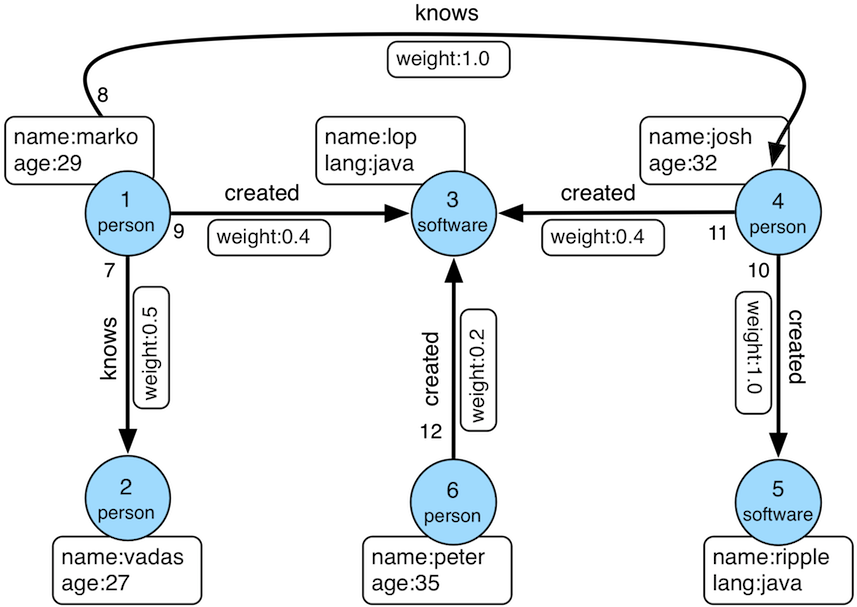
These workaround of course don’t address scenarios where the graph simply doesn’t support subgraph() and obviously increases dependence on Gremlin scripts. To see how some alternative approaches might work, consider the following traversal which produces a subgraph of “marko, who he knows over the age of 30, and what software they created”:
gremlin> sub = g.V().has('person','name','marko').
......1> outE('knows').
......2> where(inV().has('person','age',gt(30))).
......3> subgraph('x').
......4> inV().
......5> outE('created').
......6> subgraph('x').
......7> cap('x').next()
==>tinkergraph[vertices:4 edges:3]
gremlin> sg = sub.traversal()
==>graphtraversalsource[tinkergraph[vertices:4 edges:3], standard]
gremlin> sg.E()
==>e[8][1-knows->4]
==>e[10][4-created->5]
==>e[11][4-created->3]Alternative Approaches: store() and Edge Lists
If we think about the TinkerGraph a bit in the above example, it is really just a data structure (i.e. a graph data structure) that happens to organize the data we have and allows us to search it in a particular way (i.e. Gremlin). In fact, when we do query it as g.E() we effectively get a collection of Edge objects where each holds an outgoing and incoming Vertex object. If we opted to forgo the ability to use Gremlin and to analyze this data as a graph it really could have been queried without subgraph() at all:
gremlin> g.V().has('person','name','marko').
......1> outE('knows').
......2> where(inV().has('person','age',gt(30))).
......3> store('x').
......4> inV().
......5> outE('created').
......6> store('x').
......7> cap('x').
......8> unfold()
==>e[8][1-knows->4]
==>e[10][4-created->5]
==>e[11][4-created->3]Note that the data for the subgraph is no longer in graph data structure form, but is just a list of edges objects with their associated vertices. This data, captured by replacing subgraph() with store() is no less a representation of the same subgraph as the previous example, it just lacks the surrounding TinkerGraph container to allow querying it. Without the TinkerGraph, obviously this representation of the subgraph becomes something that can be returned to a non-JVM based Gremlin Language Variant. Of course, it would now be up to you to work with this raw graph data (i.e. an edge list). Perhaps you could massage the data into a native graph framework, push it to a visualization framework, convert it to GraphML for import to a tool, or whatever else that might make sense for your use case.
It’s worth pointing out that you likely wouldn’t return an actual list of Edge objects since they will return as references only. Some conversion would typically be necessary unless you only concerned yourself with id and label values on those elements:
gremlin> g.V().has('person','name','marko').
......1> outE('knows').
......2> where(inV().has('person','age',gt(30))).
......3> store('x').
......4> inV().
......5> outE('created').
......6> store('x').
......7> cap('x').
......8> unfold().
......9> project('e','outv','inv').
.....10> by(union(id(),label()).fold()).
.....11> by(outV().union(id(),values('name')).fold()).
.....12> by(inV().union(id(),values('name')).fold())
==>[e:[8,knows],outv:[1,marko],inv:[4,josh]]
==>[e:[10,created],outv:[4,josh],inv:[5,ripple]]
==>[e:[11,created],outv:[4,josh],inv:[3,lop]]The use of store() is a bit of a low-level replacement for subgraph() which in the latter “upgrades” the data container holding the edges from a List object to a Graph object.
In this form of edge list we can see the potential for repetition in the vertex property data (i.e. the “josh” vertex). There are multiple ways in which we might handle this, but one approach would be to simply store() the edges and vertices independently:
gremlin> g.V().has('person','name','marko').
......1> store('v').
......2> outE('knows').
......3> where(inV().has('person','age',gt(30))).
......4> store('e').
......5> inV().
......6> store('v').
......7> outE('created').
......8> store('e').
......9> inV().
.....10> store('v').
.....11> cap('e').
.....12> project('vertices','edges').
.....13> by(cap('v').unfold().map(union(id(),values('name')).fold()).fold()).
.....14> by(unfold().
.....15> project('e','outv','inv').
.....16> by(union(id(),label()).fold()).
.....17> by(outV().id()).
.....18> by(inV().id()).
.....19> fold()).
.....20> unfold()
==>vertices=[[1, marko], [4, josh], [5, ripple], [3, lop]]
==>edges=[{e=[8, knows], outv=1, inv=4}, {e=[10, created], outv=4, inv=5}, {e=[11, created], outv=4, inv=3}]Practical Examples and Visualization
From here, it is not hard to conceive of other formats that the subgraph might take. Consider how closely the above example matches to the “data” that a Javascript visualization library like vis.js expects:
// create an array with nodes
var nodes = new vis.DataSet([
{id: 1, label: 'Node 1'},
{id: 2, label: 'Node 2'},
{id: 3, label: 'Node 3'},
{id: 4, label: 'Node 4'},
{id: 5, label: 'Node 5'}
]);
// create an array with edges
var edges = new vis.DataSet([
{from: 1, to: 3},
{from: 1, to: 2},
{from: 2, to: 4},
{from: 2, to: 5},
{from: 3, to: 3}
]);
// create a network
var container = document.getElementById('mynetwork');
var data = {
nodes: nodes,
edges: edges
};
var options = {};
var network = new vis.Network(container, data, options);It would be quite straightforward to “subgraph” directly to that form with Gremlin directly in Javascript:
gremlin> g.V().has('person','name','marko').
......1> store('v').
......2> outE('knows').
......3> where(inV().has('person','age',gt(30))).
......4> store('e').
......5> inV().
......6> store('v').
......7> outE('created').
......8> store('e').
......9> inV().
.....10> store('v').
.....11> cap('e').
.....12> project('nodes','edges').
.....13> by(cap('v').
.....14> unfold().
.....15> map(project('id','label').
.....16> by(id).
.....17> by('name')).
.....18> fold()).
.....19> by(unfold().
.....20> project('from','to').
.....21> by(outV().id()).
.....22> by(inV().id()).
.....23> fold()).
.....24> unfold()
==>nodes=[{id=1, label=marko}, {id=4, label=josh}, {id=5, label=ripple}, {id=3, label=lop}]
==>edges=[{from=1, to=4}, {from=4, to=5}, {from=4, to=3}]Using path() for Subgraph Extraction
In addition to store() it may also make sense to try to utilize path() to extract a subgraph as the elements Gremlin traverses will all be present in the path history. The downside is that you’re left to remove duplicates and filter out path elements which may not be applicable to your subgraph. The nice thing about path() for subgraphing is that it won’t really pollute your Gremlin traversal in the way that store() does, as store() needs to appear after every step where you wish to keep a Vertex or Edge for your subgraph.
gremlin> g.V().has('person','name','marko').
......1> outE('knows').
......2> where(inV().has('person','age',gt(30))).
......3> inV().
......4> outE('created').
......5> inV().
......6> path().
......7> unfold().
......8> dedup().
......9> union(has('name').fold(),has('weight').fold()).
.....10> fold().
.....11> project('nodes','edges').
.....12> by(limit(local,1).
.....13> unfold().
.....14> map(project('id','label').
.....15> by(id).
.....16> by('name')).
.....17> fold()).
.....18> by(tail(local).
.....19> unfold().
.....20> project('from','to').
.....21> by(outV().id()).
.....22> by(inV().id()).
.....23> fold()).
.....24> unfold()
==>nodes=[{id=1, label=marko}, {id=4, label=josh}, {id=5, label=ripple}, {id=3, label=lop}]
==>edges=[{from=1, to=4}, {from=4, to=5}, {from=4, to=3}]Line 9 is a bit of a distraction as it presents a type of a hack to split the single list of mixed vertices and edges into separate homogeneous lists of each (but there is no better way to do that with Gremlin at this time - at least until TINKERPOP-2234). After that, the code is almost identical to the approach with store(), but without having to maintain the insertion of the store() step everywhere. It’s hard to say which would perform better and I imagine that it would take some testing on specific graph systems to determine which would work best. In any case, these alternatives to subgraph() should offer some options to those who need this kind of functionality, but are subject to one or more of the limitations that prevent it.