Use of local()

{kind=link}
Understanding the local() Step
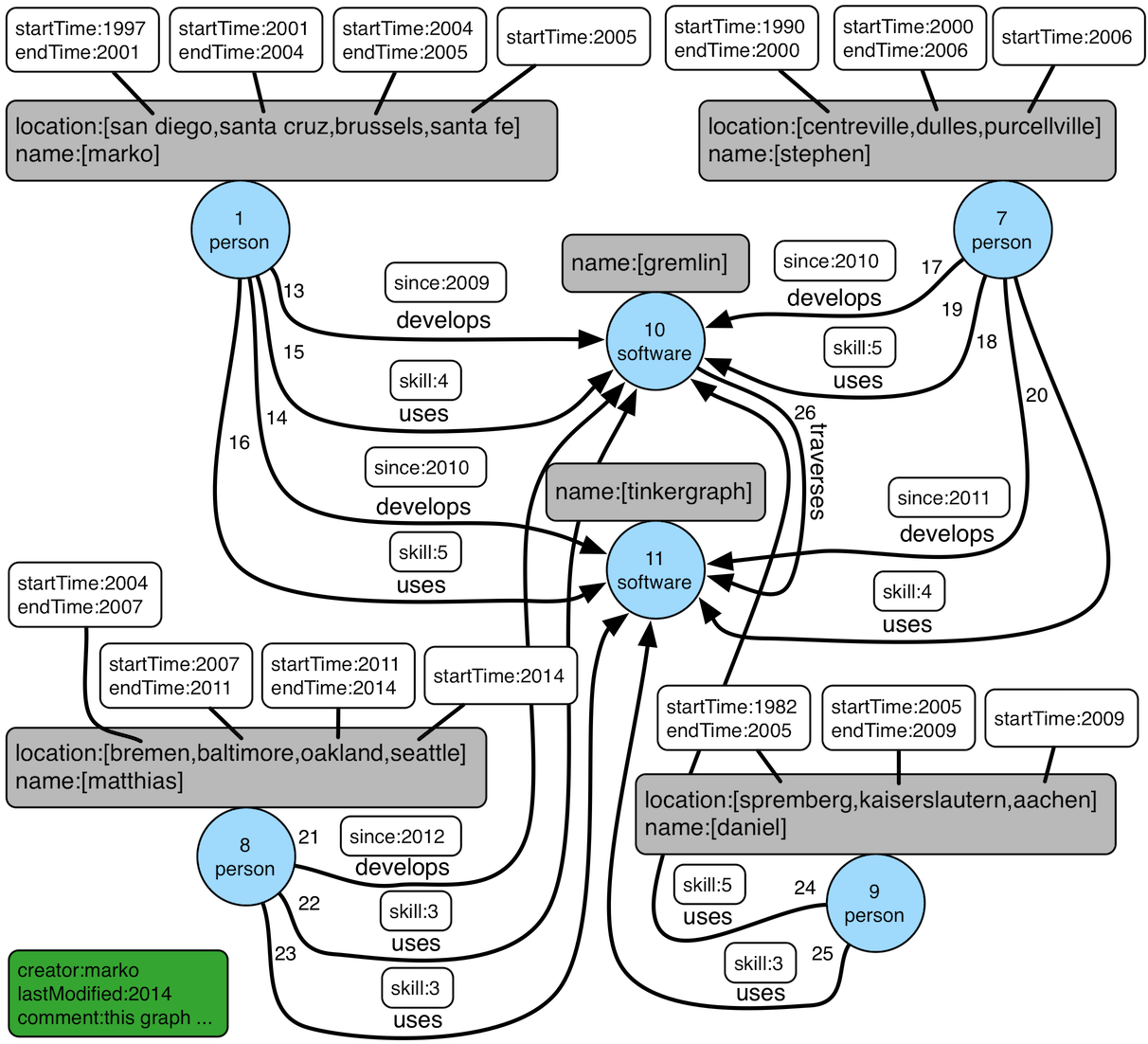
One of the more misunderstood, misused or simply unknown parts of the Gremlin language is local()-step. Its purpose is to execute a child traversal on a single element within the stream. In the following example limit(2) is applied to the stream in a global fashion and thus only two results are returned:
gremlin> g.V().properties('location').limit(2).value()
==>san diego
==>santa cruzIf we instead intended to get two properties per vertex, we would want to apply properties('location').limit(2) for each traverser in the stream that is emitted by V():
gremlin> g.V().local(properties('location').limit(2)).value()
==>san diego
==>santa cruz
==>centreville
==>dulles
==>bremen
==>baltimore
==>spremberg
==>kaiserslauternComparing local(), map(), and flatMap()
A common mistake is to think of local() as behaving like map():
gremlin> g.V().has('location').count()
==>4
gremlin> g.V().map(properties('location').limit(2)).value()
==>san diego
==>centreville
==>bremen
==>sprembergbut we can see that for four vertices with the “location” property we aren’t getting the correct results. We are only getting one location per vertex. The semantics of map()-step are one-to-one in that it only returns only the first object from the child traversal. We’d need to reduce that child traversal stream to a single object in order to get all the results. Sometimes an approach like this is necessary for cases where there is missing data and you still wish to reflect the existence of “no data” in your results. Using fold() will reduce the stream to a List and empty streams become empty lists, as shown below:
gremlin> g.V().map(properties('location').limit(2).fold())
==>[vp[location->san diego],vp[location->santa cruz]]
==>[vp[location->centreville],vp[location->dulles]]
==>[vp[location->bremen],vp[location->baltimore]]
==>[vp[location->spremberg],vp[location->kaiserslautern]]
==>[]
==>[]We can therefore see that local() is not quite like map(), but is instead more akin to flatMap(), where this step will iterate the child traversal to its entirety back to a stream:
gremlin> g.V().local(properties('location').limit(2)).value()
==>san diego
==>santa cruz
==>centreville
==>dulles
==>bremen
==>baltimore
==>spremberg
==>kaiserslautern
gremlin> g.V().flatMap(properties('location').limit(2)).value()
==>san diego
==>santa cruz
==>centreville
==>dulles
==>bremen
==>baltimore
==>spremberg
==>kaiserslauternThe Reference Documentation for local() states that, “local() propagates the traverser through the internal traversal as is without splitting/cloning it” and proceeds to include an example to demonstrate that is quite similar to the following:
gremlin> g.V().hasLabel('software').both().barrier().flatMap(groupCount().by("name"))
==>[tinkergraph:1]
==>[stephen:1]
==>[stephen:1]
==>[stephen:1]
==>[stephen:1]
==>[matthias:1]
==>[matthias:1]
==>[matthias:1]
==>[daniel:1]
==>[daniel:1]
==>[marko:1]
==>[marko:1]
==>[marko:1]
==>[marko:1]
==>[gremlin:1]
gremlin> g.V().hasLabel('software').both().barrier().local(groupCount().by("name"))
==>[tinkergraph:1]
==>[stephen:4]
==>[matthias:3]
==>[daniel:2]
==>[marko:4]
==>[gremlin:1]Traversal Optimization and the Role of Bulking
To understand the subtle difference at play here requires some discussion on traversal optimization techniques that are employed by Gremlin. Core to these techniques is the notion of bulking, which can be triggered by some form of barrier step. The barrier essentially triggers the traversal to process some or all of the traversers up to that barrier step (whether it process “some or all” is dependent upon the nature of the step itself). In performing this processing, the barrier may group or “bulk” traversers together if they are the same, incrementing a counter for each instance found thereby reducing the number of Traverser objects in memory and thus reducing the expense of the traversal itself. We can see bulking in action in profile() step where the “Traverser” column will often be smaller than the object “Count” column.
Getting back to our examples of flatMap() and local() above, we can see the direct use of barrier() step, which triggers the bulking process. Users don’t typically use barrier() directly, but it is quietly being utilized during query compilation when TraversalStrategy instances analyze the traversal and inject barrier()-step instances in places where bulking is likely to provide a performance boost. For this particular traversal, however, the query compilation process determines that no bulking is helpful as flatMap() and local() are meant to execute per incoming stream item. Executed without barrier(), without bulked traversers, the results of these two queries is identical. On the other hand, if we force bulking by way of a barrier, the difference is quite clear. The flatMap() version of the traversal unrolls the bulked traversers and processes each one with the child traversal, therefore, a vertex with a bulk of three will become three traversers to flatMap(). On the other hand, the local() version of the traversal will not unroll the bulked traversers and instead treat them as-is. We can see evidence of this happening by examinging the profile() of each traversal:
gremlin> g.V().hasLabel('software').both().barrier().flatMap(groupCount().by("name")).profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
TinkerGraphStep(vertex,[~label.eq(software)]) 2 2 0.083 30.85
VertexStep(BOTH,vertex) 15 15 0.027 10.10
NoOpBarrierStep 15 6 0.029 11.03
TraversalFlatMapStep([GroupCountStep(value(name... 15 6 0.083 31.03
GroupCountStep(value(name)) 6 6 0.046
NoOpBarrierStep(2500) 15 6 0.045 16.99
>TOTAL - - 0.269 -
gremlin> g.V().hasLabel('software').both().barrier().local(groupCount().by("name")).profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
TinkerGraphStep(vertex,[~label.eq(software)]) 2 2 0.114 43.42
VertexStep(BOTH,vertex) 15 15 0.031 12.11
NoOpBarrierStep 15 6 0.031 12.06
LocalStep([GroupCountStep(value(name)), Profile... 6 6 0.085 32.42
GroupCountStep(value(name)) 6 6 0.062
>TOTAL - - 0.263 -Note that in the flatMap() traversal the barrier() produces six traversers to flatMap(), but flatMap() unrolls them to fifteen Map objects. On the other hand, the local() version takes six traversers and operates on those six traversers without unrolling them, thus producing six Map objects which is an entirely different result. Note that counts in these Map objects effectively represent the bulk value. Add them all together and they will sum to fifteen, which is the total object count in the stream.
For most Gremlin traversals, these sorts of details will simply remain in the background, however, it’s worth keeping these subtlties in the back of your mind as traversals grow in complexity and options for performance enhancements start to become less obvious.