profile() and Indices

{kind=link}
The Price of Portability in TinkerPop
Many users choose to use TinkerPop because of the portability it brings to their code. They can write Gremlin that works equally well against many different graph databases and graph processors allowing them to easily switch from one system to another with limited pain for doing so. That flexibility does come at some price though as different graphs may optimize the same query in different ways. Moreover, TinkerPop encourages providers, through its APIs, to showcase their smarts and capabilties by offering unique optimizations to the Gremlin language to help differentiate their product. For users, subtle differences in optimizations can be a blessing as they may help improve fit their use case, but it may then also mean that they need to take more care in understanding those optimizations and evaluating the performance of their traversals to ensure they are optimized.
The Critical Role of Indices in OLTP Traversals
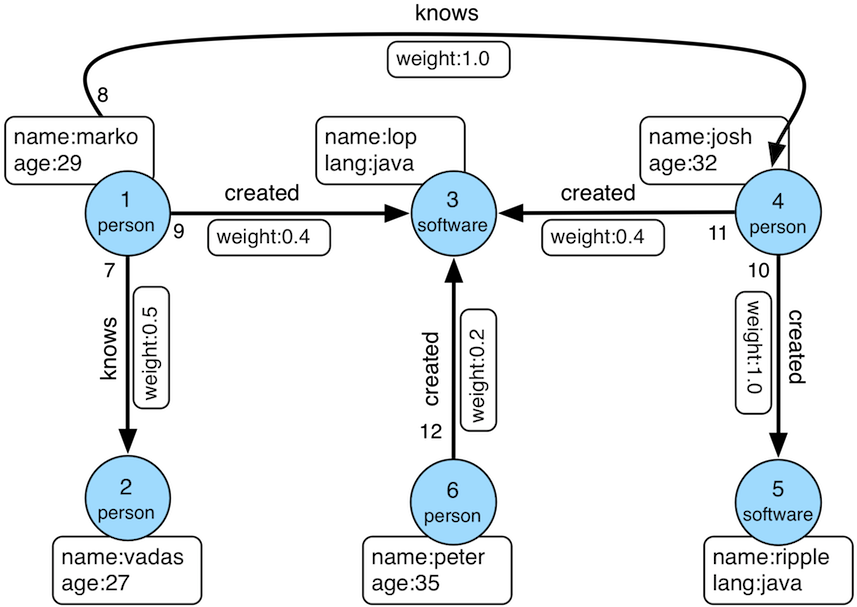
For purposes of this post, we will focus on what tends to be the single most important optimization to a traversal in OLTP: using an index to find the vertex or set of vertices that will start a traversal. For anything other than the smallest graphs, a traversal that does not hit an index will greatly underperform as it will need to execute a full graph scan in memory.
Identifying Performance Issues with profile()
The methods for identifying this problem is typically noted by simply running the query and realizing that it is unexpectedly “slow”. If you have a simple query, such as:
g.V().has('person','name','marko')and it isn’t returning immediately there’s a reasonably solid chance that you are missing an index on that vertex label and property key. Some graph implementations, like DataStax Graph are smart about such things and don’t wait for the user to see a “slow” query as a result of a missing index and simply fail the query with a message that says you are missing an index (by default). Other graph implementations, like CosmosDB, automatically index all properties so that finding a vertex on any property will utilize an index by default. However the underlying system reacts to finding those starting vertices, they key to really determining the nature of what your graph is doing is to use profile()-step.
gremlin> g.V().has('person','name','marko').profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
TinkerGraphStep(vertex,[~label.eq(person), name... 1 1 0.073 100.00
>TOTAL - - 0.073 -The above example of profile(), using TinkerGraph, may look different for other graph implementations, but the important thing we are looking for here is that the first step (i.e. V()) has immediately filtered out all vertices except for “marko”, as the “Count” and “Traversers” columns are both “1”. It is not hard to contrive some Gremlin that does not optimize as nicely as has('person','name','marko') does:
gremlin> g.V().where(values('name').is('marko')).profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
TinkerGraphStep(vertex,[]) 6 6 0.062 31.50
TraversalFilterStep([PropertiesStep([name],valu... 1 1 0.136 68.50
PropertiesStep([name],value) 6 6 0.039
IsStep(eq(marko)) 0.031
>TOTAL - - 0.199 -Comparing Query Execution Approaches
While these traversals both return the same result, we can see that their execution is quite different with TinkerGraph. TinkerGraph doesn’t optimize the where() in this case and instead returns all six vertices from V() first (again, noting “Count” and “Traversers” in TinkerGraphStep of the profile output). It then applies a filtering step that iterates over all of the “name” properties in memory to find the ones with the value of “marko”. There is the full graph scan that was discussed earlier.
A temporary side question here is: Should TinkerGraph (or perhaps all graphs) recognize this that the above queries are identical? Ideally, I think the answer is “yes”, however TinkerPop has mostly focused on developing the most common optimizations to normalize queries in ways that graph providers can get the most common benefit. I’d say that the latter query that uses where() is a bit of a corner case in the sense that most users would not attempt to write a traversal that way when has() is perhaps the most well understood step that exists in the Gremlin language. As a result, TinkerPop has not focused on this particular case as an optimization point and has left it to providers to do so instead.
Optimizing Complex Criteria with profile() Insights
Of course, some corner cases might be more consequential than others or perhaps one graph is simply smarter than another about a particular traversal pattern. It is under these scenarios where profile() can be of big help and where users might need to take a more hands-on approach to authoring their query. As an example, let’s assume that the search criteria for our starting vertices are composed of a variety of disparate vertex labels and property keys. The most obvious approach to such a traversal would be to use or() to wrap together all of that criteria as follows:
gremlin> g.V().or(has('person','name','marko'),
......1> has('software','name','lop'),
......2> has('person','age', 32))
==>v[1]
==>v[3]
==>v[4]Of course, if we profile() that traversal for TinkerGraph, we’ll find a full graph scan:
gremlin> g.V().or(has('person','name','marko'),
......1> has('software','name','lop'),
......2> has('person','age', 32)).profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
TinkerGraphStep(vertex,[]) 6 6 0.086 44.13
OrStep([[HasStep([~label.eq(person), name.eq(ma... 3 3 0.109 55.87
HasStep([~label.eq(person), name.eq(marko)]) 0.020
HasStep([~label.eq(software), name.eq(lop)]) 0.008
HasStep([~label.eq(person), age.eq(32)]) 0.019
>TOTAL - - 0.196 -The above profile shows all six vertices in the graph being passed to OrStep where they are in-memory filtered to return the three that we were looking for. We will need to rethink how this query is written in this case so that TinkerGraph can optimize this traversal. Here is one approach that comes to mind:
gremlin> g.inject(1).
......1> union(V().has('person','name','marko'),
......2> V().has('software','name','lop'),
......3> V().has('person','age', 32))
==>v[1]
==>v[3]
==>v[4]
gremlin> g.inject(1).
......1> union(V().has('person','name','marko'),
......2> V().has('software','name','lop'),
......3> V().has('person','age', 32)).profile()
==>Traversal Metrics
Step Count Traversers Time (ms) % Dur
=============================================================================================================
InjectStep([1]) 1 1 0.026 10.53
UnionStep([[TinkerGraphStep(vertex,[~label.eq(p... 3 3 0.223 89.47
TinkerGraphStep(vertex,[~label.eq(person), na... 1 1 0.004
EndStep 1 1 0.009
TinkerGraphStep(vertex,[~label.eq(software), ... 1 1 0.004
EndStep 1 1 0.008
TinkerGraphStep(vertex,[~label.eq(person), ag... 1 1 0.002
EndStep 1 1 0.009
>TOTAL - - 0.249 -The above example uses inject() to start the traversal with a single dummy traverser and then we union() together our “or” conditions with mid-traversal V() which TinkerGraph is smart enough to optimize.
Beyond Speed: Other Benefits of profile()
While this post has focused on using profile() for identifying full graph scans, hopefully it is clear that it can be used to identify other problems a traversal might face and those problems may be unrelated to a traversal that happens to be slow. For example, a traversal that is returning incorrect results might be best debugged with profile() as you can see exactly how many traversers are being processed and where they are being filtered out. Perhaps a filter is doing more work than you think it is or the graph structure is different from what you expected. Those numbers can give you some insight into that. In addition, TinkerGraph profile() metrics are somewhat simplistic. Other graphs include custom metrics that can provide deep analysis into the execution model of a query which can be quite helpful in debugging.
Learning to read the output of profile() for whatever graph system you use is an important part of improving your skills with Gremlin and should be examined for more than just the immediate point of “how long each step takes to execute.” Hopefully, this post exposed the importance of this step a bit further and shed some light on how it might be utilized to your benefit.